“20年来最大更新”,英伟达CUDA带来了什么?
2025 年 12 月,NVIDIA 推出 CUDA 13.1,此次更新被官方定位为“自 2006 年 CUDA 平台诞生以来最大、最全面的升级”。其核心亮点之一,是引入了新的编程模型 CUDA Tile。这个变化,有可能不仅仅是一项技术迭代,而是标志着 GPU 编程范式迈入一个新的阶段。
CUDA 13.1 + CUDA Tile:到底带来了什么新东西?
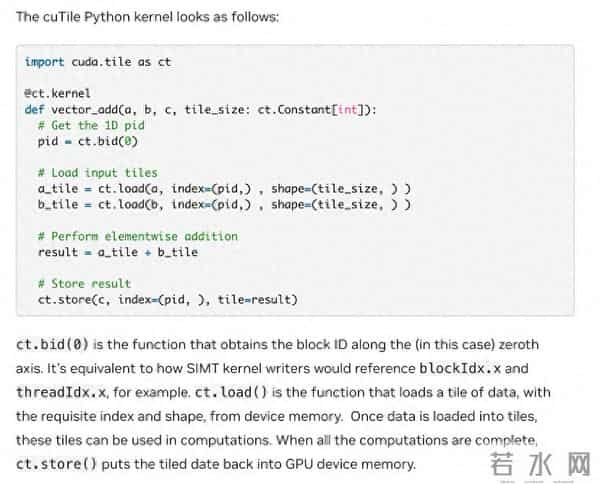
CUDA Tile 是一种基于 tile(瓦片、数据块)的 GPU 编程模型。与传统的 SIMT(single-instruction, multiple-thread,多线程单指令流)方式不同,Tile 编程允许开发者将数据组织为tile (例如矩阵块、张量块、数据块),然后对这些 tile 进行操作,由编译器和运行时负责将它们映射到底层线程、内存布局、专用硬件等资源。换句话说,开发者只需专注对块做什么计算,无需关心哪个线程做哪一部分、怎样同步的问题。
为了支持 Tile,NVIDIA 在 CUDA 13.1 中引入了虚拟指令集 (Tile IR),并配套提供 cuTile。这是一个允许用高级语言编写 tile-based kernel 的工具,通过 cuTile,开发者可以用熟悉的 Python 编写 GPU kernel,从而极大降低 GPU 编程的门槛。
根据官方描述,Tile 编程并不是要取代 SIMT,而是作为一种并存或可选的编程路径。也就是说,开发者根据需求,可以继续使用传统 SIMT,也可以在适合场景下使用 Tile。
CUDA 13.1 除了 Tile,还对运行时(runtime)和工具链进行了升级,例如对 GPU 资源调度与管理机制进行了增强,使 GPU 的多任务、并发、异构任务支持更灵活可靠。
官方同时对数学计算库(如矩阵、张量库)与底层支持的兼容性进行了优化,以更好支持未来 GPU 特性(例如 tensor core、多级缓存、异构资源分配等)。由此看来,这次更新不仅是对编程模型的改变,也为构建新一代高层、跨架构 GPU 的计算库、框架和DSL 奠定了基础。
综合来看,CUDA 13.1 + CUDA Tile 的意义,不仅在于新增一个功能或对性能进行优化,而更在于为 GPU 编程提供了一个新的、更高层、更抽象、更便捷,且可维护和可移植的选项。
GPU 越来越复杂,手动管理变得不足够
随着 GPU 架构不断演进,引入越来越多专用硬件(例如 tensor core、混合精度加速、多级缓存与内存层次、异构资源、多流或多任务支持等),底层硬件复杂度大幅增加。对开发者而言,手动管理线程、同步、内存布局、调度、硬件兼容性等负担越来越重。传统 SIMT 模型虽然灵活,但对高性能、可移植、可维护的要求而言,其复杂性和维护成本日益凸显。
在这种背景下,Tile 编程所引入的高层抽象、由系统负责的资源映射、调度、硬件利用,恰好切中了现实需求。对于 AI、大规模矩阵、张量计算、科学计算、深度学习等领域,非常具有吸引力。NVIDIA 官方也明确指出,Tile 的设计初衷是为了帮助创建适用于当前和未来 GPU 的软件。
借助 cuTile (Python DSL),许多过去因为不擅长 CUDA C、对底层 GPU 编程不熟悉的数据科学家、研究者,也可能开始编写 GPU 加速代码。对于深度学习、科学计算、AI 团队或高校研究机构来说,这意味着 GPU 加速不再只属于少数 GPU 专家核心团队,而可能被更多人使用。此外,对于那些需要跨 GPU 架构的团队来说,一次编写、多代兼容的可能性,将大大降低重构、优化和维护的成本。
(来源:英伟达)
同时,Tile 提供了一条新的 GPU 编程路径。这条路径不仅对单个项目或团队有利,也可能促使整个 GPU 软件生态走向更高层、更抽象、更通用、更易维护和跨架构兼容。这种变化对未来 GPU 编程规范化、标准化以及广泛应用具有潜在推动力。这次更新可能不仅仅是一个版本号的提升,而是 GPU 编程范式的一次质变。
从硬核到普惠的转折点
在技术社区中,CUDA 13.1 的发布引发了截然不同的两种情绪,而这恰恰印证了这次更新的变革性。
对于资深的高性能计算(HPC)工程师而言,反应是复杂的。一方面,他们习惯了对每一个寄存器、每一块共享内存(Shared Memory)的精细控制,CUDA Tile 这种将细节交给编译器的做法,不可避免地引发了关于性能上限的讨论。正如在 Reddit 和 Hacker News 上一些硬核开发者所担忧的:“我们是否正在用极致的性能换取开发的便利性?”
然而,对于更广泛的数据科学家和 AI 算法工程师群体,这无疑是一个好消息。长期以来,将 PyTorch 或 TensorFlow 中的高层逻辑转化为高效的 CUDA 核心代码,是一道难以逾越的技术鸿沟。cuTile Python 的出现,实际上是在填平这道鸿沟。它意味着开发者不再需要精通 C++ 和计算机体系结构,仅凭 Python 就能触达 GPU 80% 甚至 90% 的理论性能。这种性能平权可能会引爆新一轮的 AI 算子创新。当编写一个高效的 Attention 变体不再需要两周的 C++ 调试,而只需一下午的 Python 脚本时,创新的飞轮将转得更快。

(来源:Shutterstock)
竞争格局的深层变化:从代码兼容到架构抽象
在 CUDA 13.1 之前,竞争对手(如 AMD 的 ROCm 或 Intel 的 OneAPI)主要的追赶策略,是通过兼容层(如 HIP)来转译现有的 CUDA 代码。这种策略主要基于 C++ 语法的相似性。
然而,CUDA Tile 的出现改变了这种竞争的维度。通过引入 Tile IR(虚拟指令集)和高层抽象,NVIDIA 实际上是在硬件和软件之间增加了一个更厚的中间层。
当开发者开始习惯使用 Tile 编程模型,更多地关注数据块的逻辑而非底层线程调度,代码与底层硬件的解耦程度变得更高。这意味着,代码的执行效率将更多地依赖于编译器如何理解和优化这些 Tile 操作。对于竞争对手而言,要支持这种新模式,仅仅做代码转译是不够的,还需要构建一个同样智能的编译器来处理这些高层抽象,这无疑增加了技术对齐的难度,也客观上提高了生态系统的粘性。
面向云环境的演进:Green Contexts 的实际价值
除了编程模型,CUDA 13.1 在运行时环境上的改进,特别是 Green Contexts 从驱动层走向运行时 API,反映了 GPU 使用场景的结构性变化。
在 Blackwell 架构时代,GPU 已经从单纯的加速卡转变为数据中心的核心算力单元。随着单卡算力(如 B200 系列)的大幅提升,对于许多单一任务来说,独占整块 GPU 往往是一种资源浪费。
Green Contexts 允许开发者或系统管理员在运行时更安全、更细粒度地划分 GPU 资源(SM)。这在技术上解决了多任务并行时的干扰问题,使得 GPU 能够像 CPU 一样,高效、稳定地同时处理多个用户的任务。对于云服务商和企业内部的算力调度来说,这直接提升了昂贵硬件的利用率和投资回报率。
新的挑战:抽象化带来的黑盒隐忧
当然,这种向高层抽象的演进也并非没有代价。CUDA Tile 带来的最大挑战在于调试与性能优化的透明度降低。
在传统的 SIMT 模式下,开发者清楚地知道每一行代码对应什么指令,数据在寄存器和内存间如何移动。而在 Tile 模式下,编译器接管了大量的数据布局和映射工作。一旦性能不如预期,或者出现非功能性 Bug,开发者可能会发现很难像以前一样精准定位问题。
虽然 NVIDIA 在 Nsight 工具链中增加了对 Tile 的支持,但如何让开发者理解编译器的优化逻辑,而不是面对一个无法干预的“黑盒”,将是这一新模式能否被资深开发者广泛接受的关键。此外,这也意味着软件性能将更加依赖于 NVIDIA 编译器团队的优化水平,而非开发者个人的微调能力。
CUDA 13.1 的发布,本质上是 NVIDIA 应对硬件复杂度爆发的解决方案。通过 CUDA Tile,NVIDIA 试图建立一种新的分工模式:开发者专注于高层的算法逻辑与数据流,而将复杂的硬件适配工作交给编译器和运行时环境。
这不仅降低了高性能计算的门槛,也让 CUDA 平台在异构计算和云原生时代,具备了更强的适应性和生态掌控力。对于开发者而言,这或许意味着是时候调整思维习惯,从微观的线程管理,转向宏观的数据块编排了。
参考文章:
1.
2.
3.
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。





