全球第一!百度甩出0.9B王炸,这次DeepSeek真被“偷家”了?

别只盯着DeepSeek看了。
就在大伙儿还在为DeepSeek的狂飙热血沸腾时,1月29号,百度悄咪咪地干了一件大事。
它开源了一个叫 PaddleOCR-VL-1.5 的模型。
很多人一听“OCR”(文字识别),第一反应就是翻白眼:
“都2026年了,怎么还在折腾这种上古技术?这不就是扫描仪干的事吗?”
如果你这么想,那这一波AI红利,你注定要错过了。
这事儿背后,藏着中国AI下半场最残酷、也最真实的竞争逻辑。
一、让你想摔手机的“最后一公里”
咱们先不聊技术,聊聊生活。
你肯定有过这种崩溃时刻:
为了报销,拿着手机对着皱巴巴的发票咔嚓一拍,想让AI自动填表。
结果呢?
因为纸上有个折痕,金额“1000”被认成了“100”;
因为拍摄角度稍微歪了一点,表格里的行和列直接串了门。
最后还得是你,一边骂娘,一边手动一个个敲数字。
这就是过去OCR的死穴:它能认字,但它看不懂“纸”。
它只能伺候那种像刚出厂一样平整、完美的文档。但真实世界是什么样的?
是揉成团的小票,是贴得歪七扭八的快递单,是有反光、有阴影的合同。
在实验室里跑分99%,一到你手里就歇菜。
这就是产品经理最痛恨的“最后一公里”——这一步跨不过去,你模型参数再大,对用户来说也是零。
二、百度这次,干了件很“贼”的事
这次百度放出的PaddleOCR-VL-1.5,最狠的地方不在于它认字多准,而在于它长了“脑子”。
它搞了个全球首创的“异形框定位”。
说人话就是:AI终于能看懂“歪”的纸了。
哪怕你拍的合同是梯形的,发票是被揉过的,它不再是傻乎乎地把像素翻译成字,而是先理解这张纸的物理结构(哪里折叠了、哪里扭曲了),再还原它的逻辑结构(这是表格、那是标题)。
在文档阅读顺序预测上,它的错误率直接砍半。
这意味着什么?意味着在处理复杂的财报、合同时,它比很多所谓的大模型都要聪明得多。
但这还不是最吓人的。
最吓人的是它的“性价比”。
这个模型只有 0.9B 参数。
这是什么概念?
意味着你不需要那种几万块的显卡,拿着你的MacBook,甚至配置好点的普通笔记本,就能流畅地跑起来!
三、数据不会撒谎:吊打DeepSeek?
是骡子是马,拉出来遛遛。
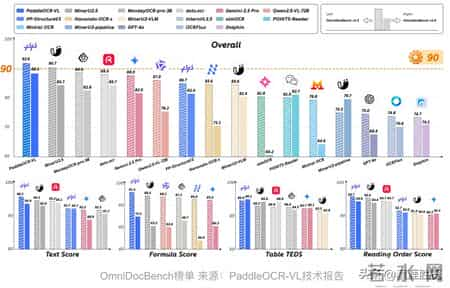
在全球公认最难的 OmniDocBench V1.5 榜单上:
百度这次直接领先了超过3个百分点。而且在扫描、弯折、屏幕拍照这些“地狱级”场景里,更是全面碾压。
你不得不服,作为国内最早死磕OCR的大厂,百度手握1700多件专利,这护城河挖得确实深。
四、为什么大厂突然都在抢OCR?
细心的人可能发现了,最近半年,OCR这个赛道突然挤爆了。
为啥?
因为大佬们都想明白了一件事:如果大模型是AI的大脑,那OCR就是AI的眼睛。
没有高精度的OCR,大模型就是个“瞎子”。
谁掌握了OCR,谁就掌握了现实世界通往数字世界的“唯一入口”。
五、中国AI的“三国杀”格局,定了!
把视野拉高,看看2026年1月的这几天发生了什么:
这根本不是巧合,这是中国AI的“三国杀”。
- 百度(文心):打的是“体系战”。 有超级大脑(文心5.0),有特种兵(PaddleOCR),还有数字人。它是正规军打法,主打一个“全”。
- 阿里(千问):打的是“场景战”。 绑定电商和支付,它是要帮你赚钱、提效率。
- DeepSeek:打的是“游击战”。 它是技术极客,用小参数、低成本去撬动市场,主打一个“巧”。
这就对了!大家不再盲目卷参数,而是开始拼落地,拼谁能解决具体问题。
六、给咱们普通人的搞钱建议
说了这么多,这对你有啥用?
别光顾着看戏,机会在脚下。
- 爱上“小模型”:
别总盯着GPT-5。像PaddleOCR这种0.9B的小模型,开源、免费、能跑在本地。这才是你能掌控的金矿。
- 抓住“文档变现”:
搞工具: 开发个能自动整理读书笔记、会议记录的插件,卖给考研党、文字工作者。
搞服务: 帮中小企业做发票数字化、合同比对。这些需求巨大,但他们用不起大公司的定制方案。
AI竞争已经从“造模型”变成了“用模型”。
PaddleOCR-VL-1.5 就是百度递给你的一块免费的乐高积木。
你是选择把它放在角落吃灰,还是用它搭出属于你的城堡?
这取决于你。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。



